Usage¶
Preparation¶
- Firstly, user need to invoke make install command. It will install tools such as
- KenLM
- OpenCV for Python
- NLTK
- Vowpal Wabbit
- After successful installation user need to prepare training set or testing set depending on usage. These sets should be put into:
- training to train directory
- testing to test-A or dev-0 directory
- Directories should contain:
- newspapers in .djvu file format
- in.tsv files where newspapers titles and obituaries coordinates are kept
Train¶
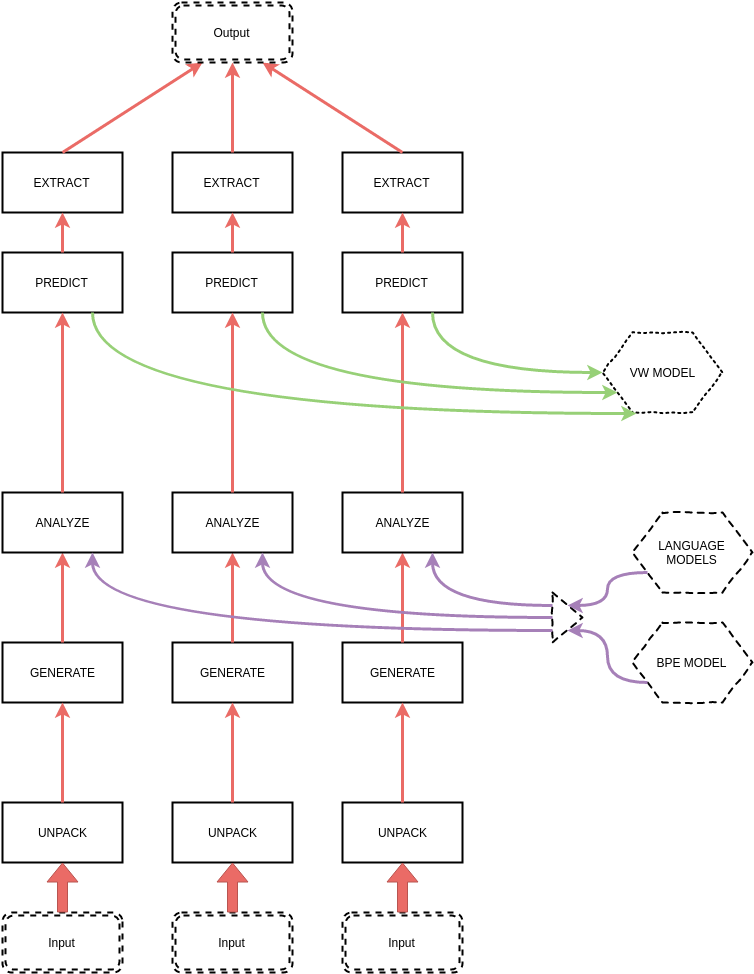
To train vowpal wabbit model make train -j X command need to be invoked, where X is number of newspapers processed at the same time (train without flag -j means that just one newspaper will be processed at the same time).
During runtime the newspapers are being unpacked. The metadata, xml of page and its text are being extracted, the page is being saved into TIFF file. At the end every text layer of the newspaper pages are being merged into one text file which corresponds to text in whole newspaper. After unpacking the place takes generate process. During this step the rectangles are being generated basing on edges noticed by computer vision algorithms. When rectangles are generated the classify process gives them labels “-1” when the rectangle isn’t an obituary and “1” when it is an obituary. Nextly LM and BPE model are being trained. In order to make LM corpora must be created:
Corpus of necrologies
Corpus of pages with necrologies
BPE model is being trained on text layer of the newspaper extracted in unpack process. After training the analyze step is being running. During that process graphic and text features are being created and also language models are being queried. That features are necessary to create the input to vowpal wabbit model which is trained at the end of train process.
Take a look into manual if you want to gain more information about invoking specific steps of training. It’s useful when ones need to re-train model without unpacking all of the newspapers again.
Test¶
In this phase trained vowpal wabbit model is being tested. Just like in train point, user need to invoke make test -j X or make dev -j X command, where X is number of newspapers processed at the same time (test without flag -j means that just one newspaper will be processed at the same time).
Steps like unpacking and generating are same for both – test and train step. After that graphic, text and language models features of the newspaper are being created in analyze step. Files created during analyze are taken for prediction step – obituaries are being predicted in the newspapers.
Take a look into manual if you want to gain more information about invoking specific steps of testing. It’s useful when ones need to re-test model without unpacking all of the newspapers again.
Cut necro¶
After testing - out.tsv file is created. It contains coordinates of the obituaries found in appropriate newspaper (from in.tsv). Command make test-cut or make dev-cut merges both of files and cut found obituary from the newspaper. The result can be found in test-A/obituaries or dev-0/obituaries directory.
Cleaning and purging¶
By clean is understood removing *out.tsv files, train files, corpora, arpa and klm files from LM directory, and BPE model. Purging removes also vw files and predict. Take a look into manual if you want to gain more information about invoking specific ways of purging and cleaning. formation about invoking specific ways of purging and cleaning.
Train flow¶
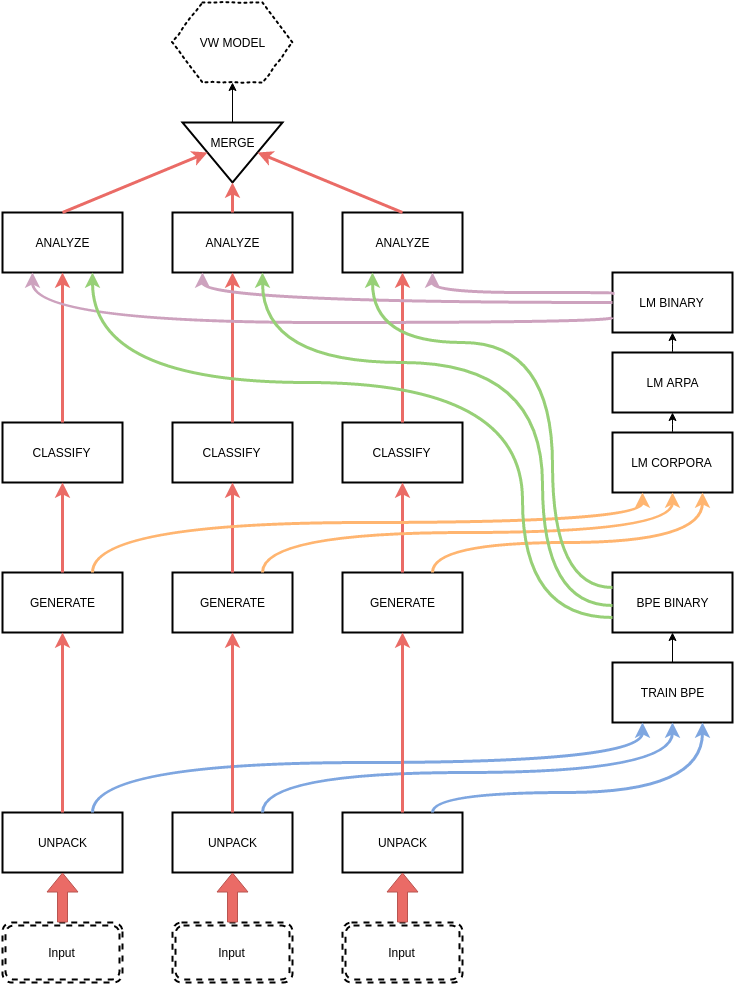
Test flow¶